
In this post I’ll cover creating the actual machine learning model to predict bets and how it worked for the fist slate of games. If you haven’t read the background on this project, I’d point you back to my first post in this series where I described the point of the holiday project.
Creating the Model
The first step is made miraculously easy by AWS Sagemaker. I needed to run the data I described gathering and cleaning in the previous post through AWS Sagemaker’s AutoPilot. I took a beginner course in ML at the beginning of the holidays before embarking on this project, and I learned enough to know that it would take me a year to do the data transformation, model building/testing, and model tuning that AWS SageMaker can do in a couple hours. I simply pointed at the problem and let AWS try 100 different models for each of the four questions (should I make an Over Bet? Under Bet? Bet on the Home Team? and Bet on the Away Team?) with data from all of the games from this season.
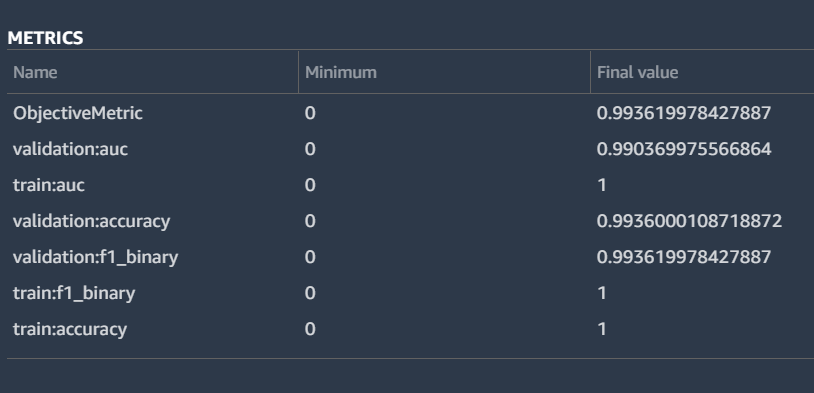
Metrics for the Winning “Under” Bet Model 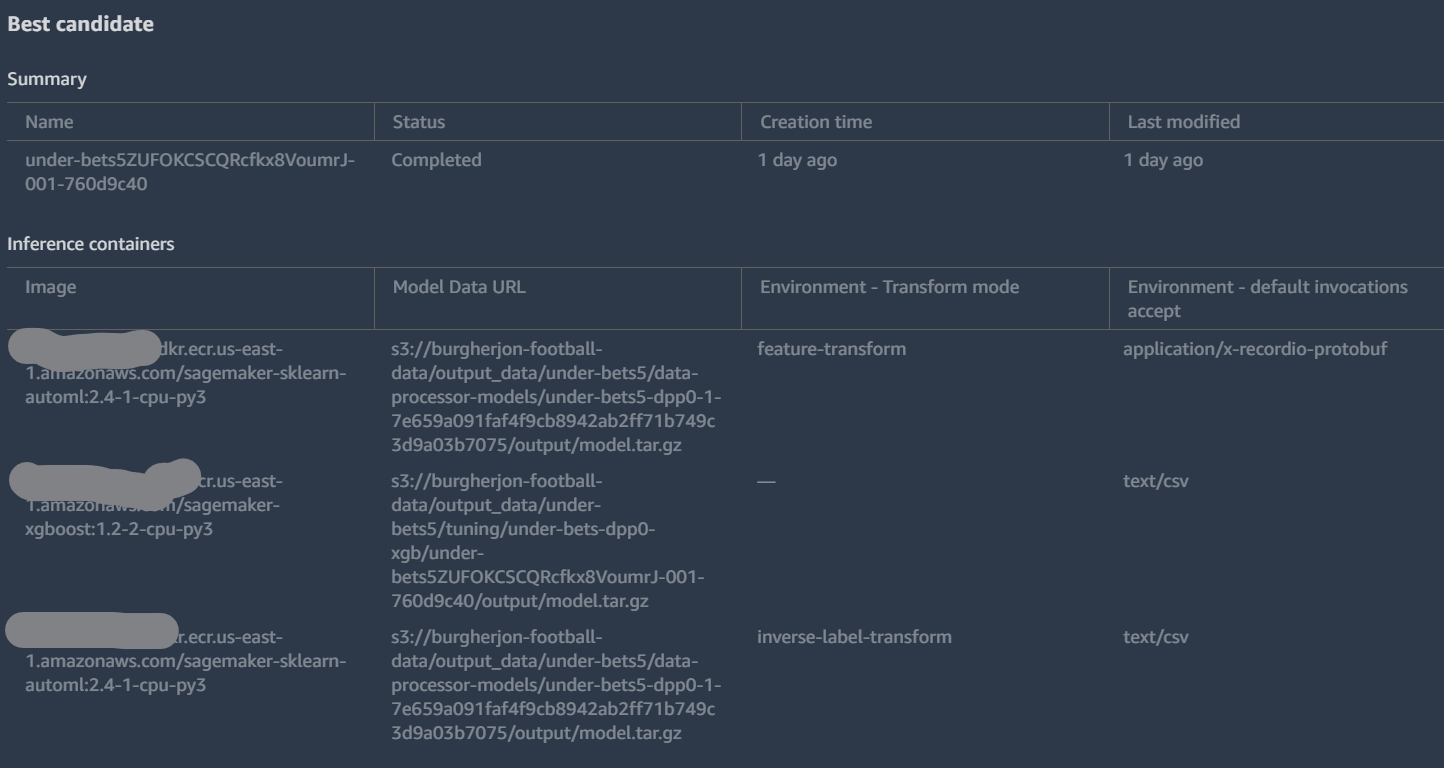
Details on the Model 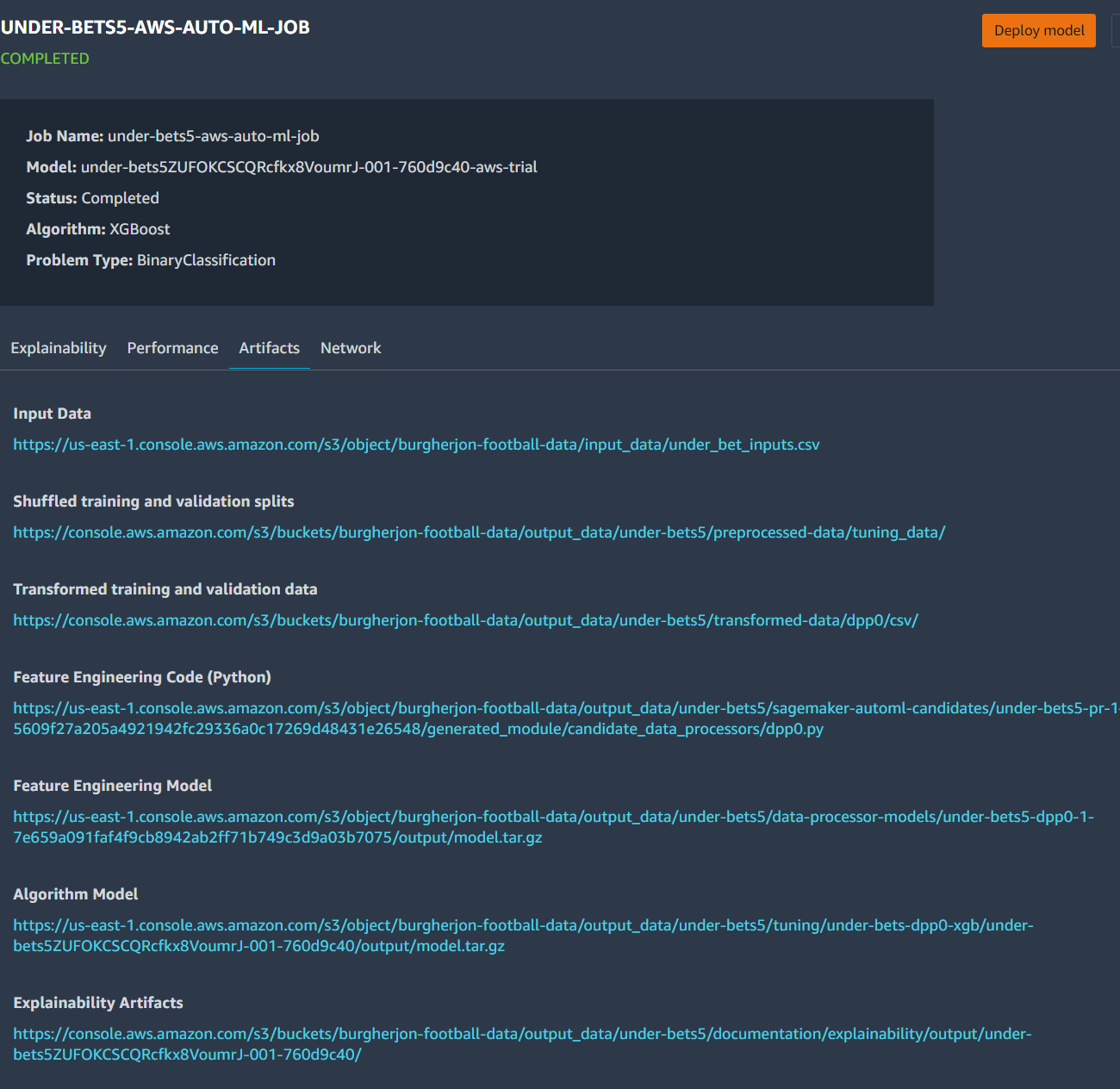
Details on the Artifacts Created
The winner in all four cases was an XGBoost algorithm. I’ve included both the model details and the metrics I got back above. As you can see, the F1 score for the classification got to .994. In a model designed to measure something so luck intensive, this is an obscenely high score. I think it can be explained by the fact that I had to duplicate some of the data since I didn’t have enough data to meet SageMaker’s minimums. The model almost certainly over tuned itself to criteria that aren’t actually as predictive as you’d think. If it manages to pick 99.4% of the games, I’ll be retired soon.
Deploying and Running the Model
Based on the lack of online literature on how to actually deploy/use models in SageMaker, you’d think it would be the easiest part. I did NOT find it to be easy. It’s the kind of thing that once you’ve done it a few times, I’m sure it becomes simple. However, for me, on my first time creating an AI it was anything but.
The main problem I ran in to was on deploying a model I could actually use later. I knew from the beginning that I was only going to want to use the model periodically and so I wanted to deploy it in a way where it could run cheaply. When I discovered that “Serverless Endpoints” were available I was excited! Imagine if I could deploy my model in such a way that I’d only be charged to use it the 15 times per week I actually need it without spinning up and shutting down instances! I looked at the picture above labeled “Details on the Model” and noticed that it had three different containers to be provisioned. I picked the middle one since it’s input/output was CSV and created a serverless endpoint. For under bets and home games this gave me gibberish results. Instead of picking 1 or 0 (bet or don’t) the model returned decimals. The other two models didn’t work at all. I tried recreating the models, redeploying the models, looking for information on how to interpret results. All of this assumed I was messing something up somewhere along the way. What I finally realized is that the three containers that made up the model weren’t “options” but all needed to work in concert. I gave up and decided to just rack up a high AWS bill and deploy the models from the “Deploy Model” button in the SageMaker AutoPilot results. This finally worked. If you’re curious, I kept my code for deploying a serverless model… I still think it’s an awesome feature.
Another few hours wrestling with formatting the input data correctly (all the same data I collected for the training data needed to be found for the games I wanted to predict). You can find my code for formatting this data on my git repo. While the code is written in a Jupyter Notebook, you’ll notice I’m using the AWS parameter store to retrieve my login for my score provider, the notebook has been written to only predict games that start in the next 30 minutes, and the playbook actually adds the bets directly to my database. This was all done because I am going to be turning this in to a Lambda function later in the week so that the BOOK-E can play in the league without any human intervention. More on this in another blog post.
I did get a few games where I got conflicting results. For example, places where I should place both a bet on the home team and on the away team. Whenever this happened, I just chose not to make a bet (you can see this in the python code). I only got the model running just before the 1pm games, so I could only make one prediction (on the Titans). In the 4pm games I had the algorithm running and WALL-E’s picks looked like this:
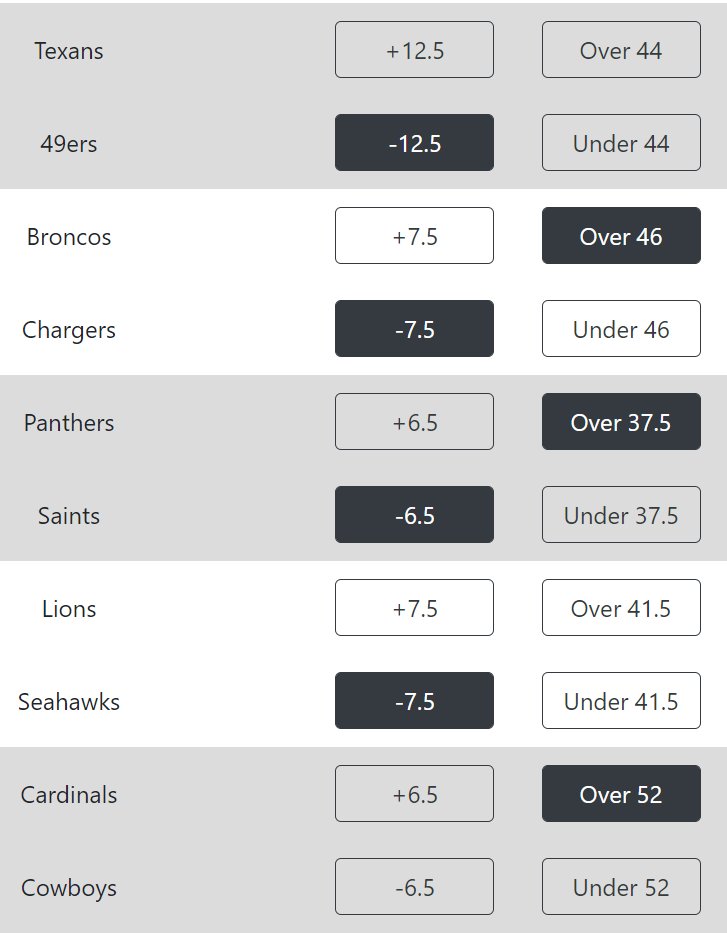
How Did BOOK-E Do?
Actually pretty good. Overall he was 6-2. There’s an almost 15% chance that a coin flip would have been that good in only 8 games though. You’ll just have to let me keep you posted.